EffiSciences

Started on Jan. 6, 2023
This challenge is related to underspecification problems [1,2] in which multiple hypothesis can explain the data, as well as the problem of robustness to distributional changes [3]. For example, classifiers trained to recognize the lungs of hospitalized patients with and without pneumothorax cannot be used preemptively on untreated patients because the classifier will recognize the chest drain (an easily identifiable straight line) and not the causative features of the disease [4]. This problem is quite general and is likely to arise whenever an ML algorithm is to be used on data that is different from the training data (selection bias: labeled data is generally simpler than unlabeled data and simpler than the data encountered in production). For example, in the field of sustainable development, most ML models are trained on a sample of rich countries that are very different from the countries where the model will be deployed. In general, we want to use past data to predict the future, but the future is not the past.
Why did a network trained to identify collapsed lungs ended up detecting chest drains?
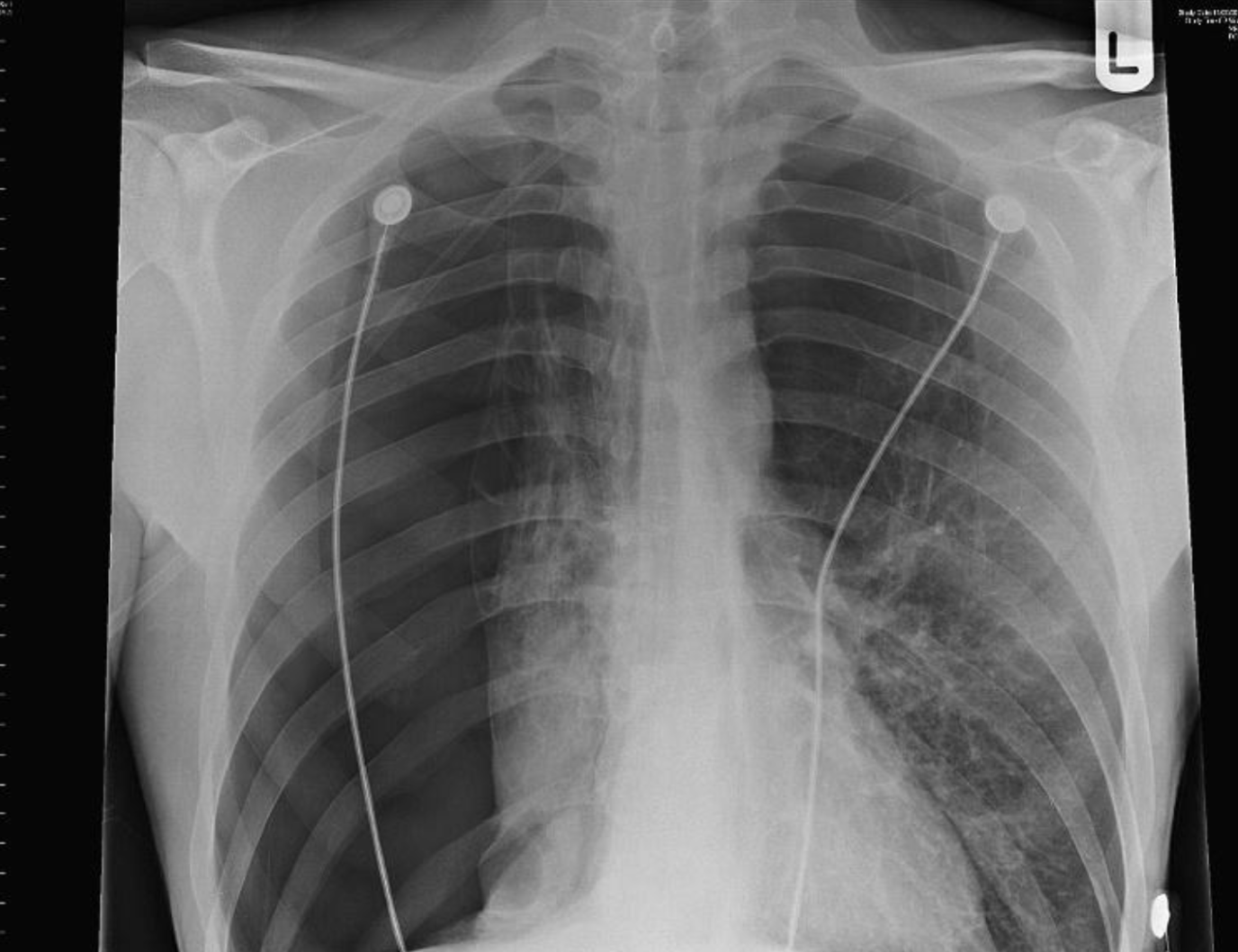
Above: X-ray of a patient with two chest tubes - a treatment for collapsed lungs. Chest drains are visually much simpler than collapsed lungs, and the two features are correlated, so a classifier could perform well by learning to identify the simpler feature, but would not perform well on a patient before surgery.
Indeed, the training data did not help to distinguish true collapsed lungs from chest drains - a treatment for collapsed lungs. Chest drains are visually much simpler than collapsed lungs and the two features were correlated, so the algorithm was able to perform well by learning to identify the simpler feature.
Classifiers typically learn the simplest feature that predicts the label, whether or not it matches what the humans had in mind. Human monitoring can sometimes detect this error, but it is slow, expensive, and not completely reliable (because the human may not realize what the algorithm is doing until a potentially dangerous error is made).
Detecting the "wrong" feature means that the classifier will fail to generalize as expected - when deployed on x-rays of real humans with real, untreated collapsed lungs, it will classify them as healthy, since they do not have a chest tube.
What if misleading correlations are present in the training dataset?
human_age is an image classification benchmark with a distribution change in the unlabeled data: we classify old and young people. Text is also superimposed on the images: either written "old" or "young". In the training dataset, which is labeled, the text always matches the face. But in the unlabeled (test) dataset, the text matches the image in 50% of the cases, which creates an ambiguity.
We thus have 4 types of images:
Age young, text young (AYTY),
Age old, text old (AOTO),
Age young, text old (AYTO),
Age old, text young (AOTY).
Types 1 and 2 appear in both datasets, types 3 and 4 appear only in the unlabeled dataset.
To resolve this ambiguity, participants can submit solutions to the leaderboard multiple times, testing different hypotheses (challengers may consider solutions that require two or more submissions to the leaderboard).
We use the accuracy on the unlabeled set of human_age as our metric.
At the end of the challenge, the different teams will have to send their code to crsegerie@gmail.com with the heading: "Challenge Data - Submission". The awarding of the prize will be conditional on this submission and on compliance of the following rules:
Participants are not allowed to label images by hand.
Participants are not allowed to use other datasets. They are only allowed to use the datasets provided.
Participants are not allowed to use arbitrary pre-trained models. Only ImageNet pre-trained models are allowed.

We have 4 types of colored images of size 218x178 pixels: Age Young Text Old (AYTO), Age Young Text Young (AYTY), etc. We provide:
a labeled set: 20000 images (either AOTO or AYTY)
an unlabeled set: about 70000 images of the four types (mixing rate of 50%, the four types being present in equal proportion).
human_age weighs 630 Mb and is a variant of the CelebA dataset [5].
In the supplementary material, you will find the human_hair dataset in which all labels are public to allow participants to iterate more easily before tackling human_age which is more complicated.
In human_hair, instead of classifying age, we classify hair color which is a much simpler feature to classify than age. human_hair weighs 14 Mb.

In order to start working on the two datasets, you can begin with the Colab "Starting Pack" which will allow you not to spend time on the infrastructure, data loading and the expected csv format.
![]()
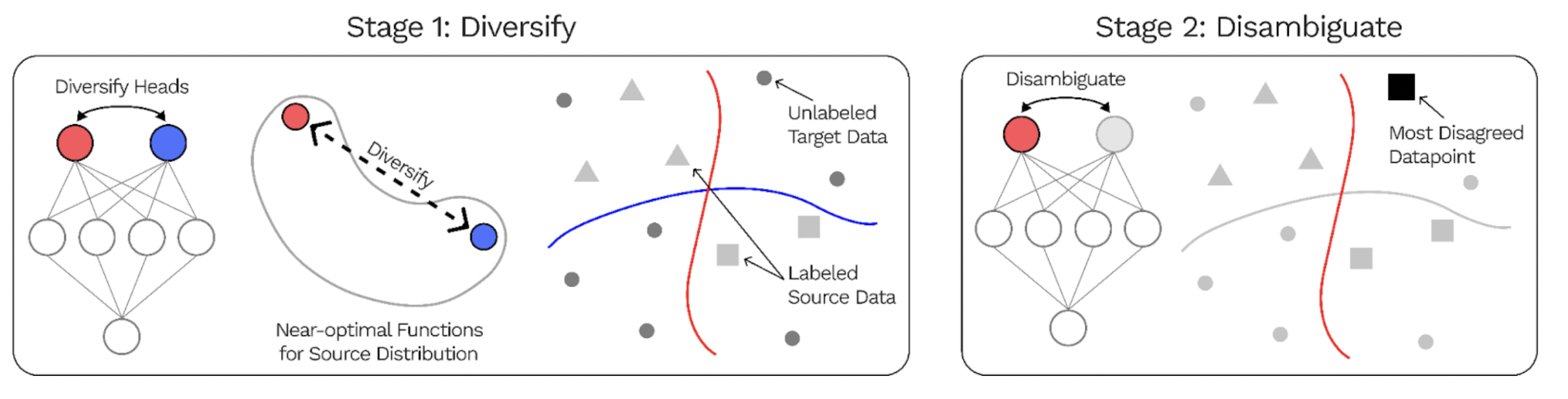
The DivDis paper [6] presents a simple algorithm to solve these ambiguity problems. DivDis uses multi-head neural networks, and a loss that encourages the heads to use independent information. Once training is complete, the best head can be selected by testing all different heads on the validation data.
DivDis achieves 64% accuracy on the unlabeled set when training on a subset of human_age and 97% accuracy on the unlabeled set of human_hair.
GitHub : https://github.com/yoonholee/DivDis
[1] Armstrong, S; Cooper, J; Daniels-Koch, O; and Gorman, R, “The HappyFaces Benchmark”,” Aligned AI Limited published public benchmark, 2022.
[2] D'Amour, Alexander, et al. "Underspecification presents challenges for credibility in modern machine learning." arXiv preprint arXiv:2011.03395 (2020).
[3] Amodei, Dario, et al. "Concrete problems in AI safety." arXiv preprint arXiv:1606.06565 (2016).
[4] Oakden-Rayner, Luke, et al. "Hidden stratification causes clinically meaningful failures in machine learning for medical imaging." Proceedings of the ACM conference on health, inference, and learning. 2020.
[5] Liu, Ziwei, et al. "Large-scale celebfaces attributes (celeba) dataset." Retrieved August 15.2018 (2018): 11.
[6] Lee Yoonho, Yao Huaxiu, Finn Chelsea, "Diversify and Disambiguate: Learning From Underspecified Data", arXiv preprint, arXiv:2202.03418v2 (2022).
Files are accessible when logged in and registered to the challenge
Challenge data is supported by:
